
How Dotscience manages thousands of tunnels to create a better Data Science environment
A case study on how Dotscience utilizes Webhook Relay tunnels
The product
The core tenet of the Webhook Relay service is receiving and processing HTTP requests. When used with bidirectional tunnels it's a 1:1 relationship that simply exposes the underlying service to the internet. Our client software can run on any machine (Windows, MacOS, Linux x86 and ARM) as well as Docker containers, Kubernetes deployments.
When used with webhook forwarding, relationship becomes N:N, meaning that there can be multiple public endpoints that will be routing to multiple destinations that are either internal (private network) or public destinations. All HTTP requests can be transformed on arrival to our system or before getting dispatched. A single webhook can be transformed into a new request that is tailored for any API.
Webhook Relay masterplan
- Remove all friction from exposing internal services to the internet for easy access.
- Securely let traffic in for sensitive systems (CI/CD) using unidirectional forwarding.
- Transform webhooks, when needed.
Dotscience
Dotscience is a Machine Learning & Data Science platform that allows engineers and data scientists easily utilize compute infrastructure and track their data in a reproducible way.
Since it's an end-to-end Data Science platform, in this article we will only focus on Jupyter notebook service and ML model deployment for inference.
Use case: runners anywhere
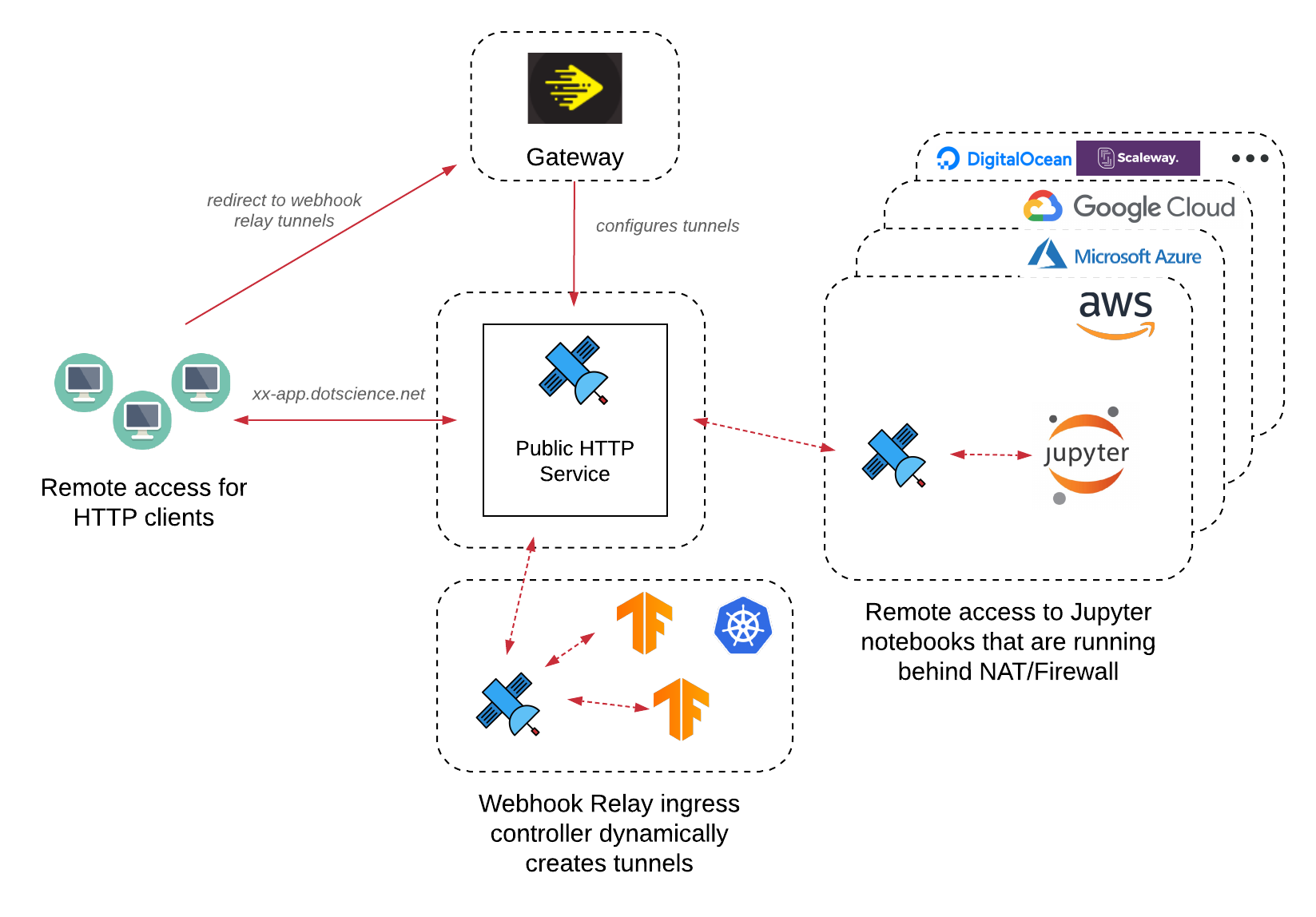
The potential problem with Dotscience runners was that they could be started anywhere - in the Kubernetes environment, on a simple virtual machine with docker that is running in a cloud environment, or in a private data center. This required easy access to the Jupyter, free from any restrictions regardless of the environment.
The solution was to adopt Webhook Relay tunnels to enable Dotscience users to reach Jupyter notebook servers running on local or remote compute nodes. Dotscience agents would start both Jupyter, Dotmesh (data persistence daemon), and Webhook Relay container. This container would open a tunnel and serve Jupyter notebooks under a URL that's similar to xyz.tasks.dotscience.com. Dotscience dashboard would then open it in an iframe and supply authentication token.
Tunnel management is completely automated with domains and routing configuration created during runtime. During normal operation, tunnels might last for a few minutes or even days. There can be thousands of tunnels created and deleted within hours. Since we are utilizing wildcard domains for the tunnels, TLS becomes a simple thing to manage.
Use case: ML predictions on any Kubernetes environment
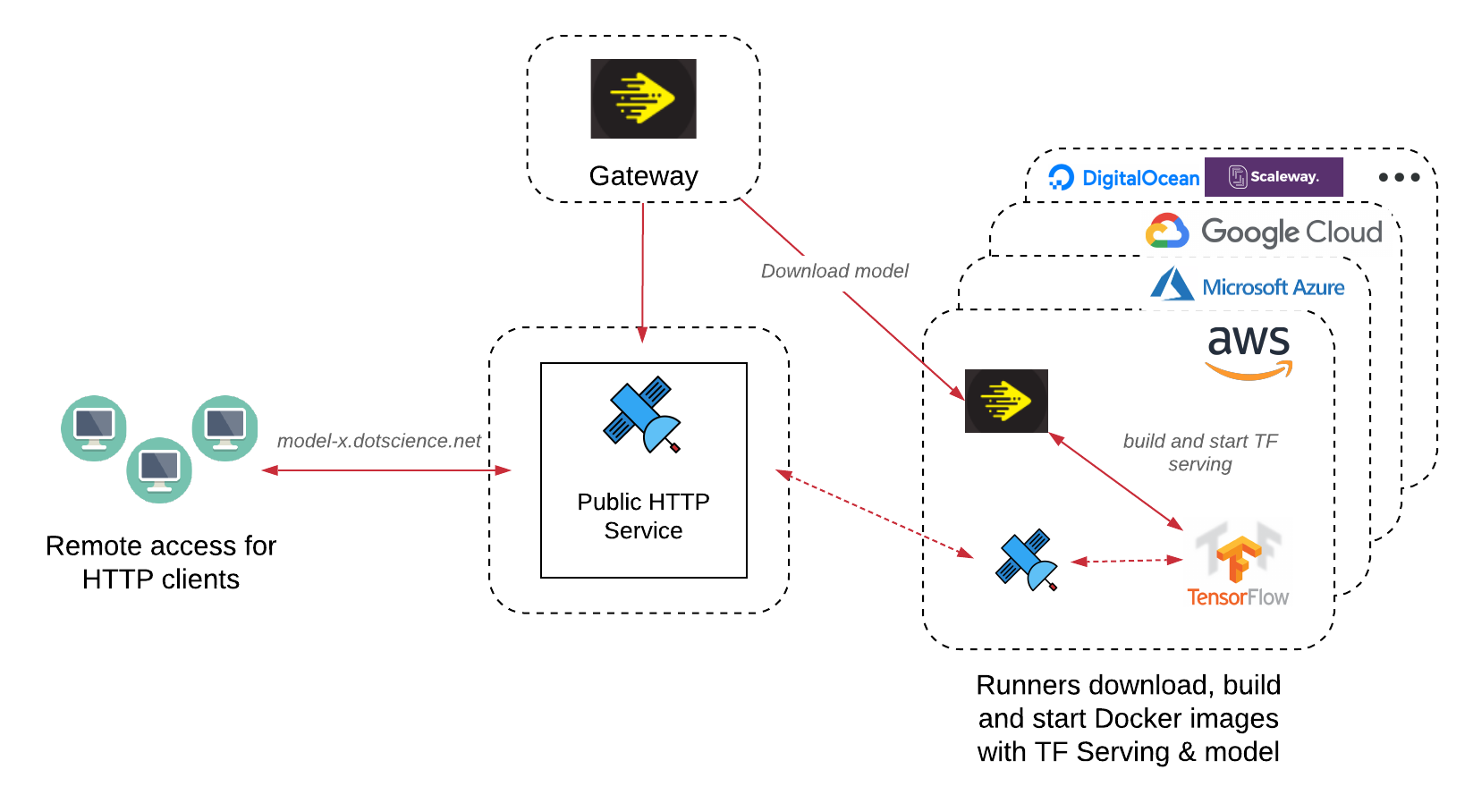
As with Dotscience runners for Data Science and ML model training on Jupyter notebooks, there is a need for easy access to deployed models on Kubernetes clusters. Since Dotscience provides a deployer model where the user just needs to start the operator, they might not always be able to configure load balancing.
For this, Webhook Relay ingress controller comes into play where we can provide access to the models whether it's running in GKE, EKS or Minikube:
Key results
- Global region for Dotscience cloud offering deployed.
- Each self-hosted Dotscience stack includes a standalone Webhook Relay tunneling service for easy access.
- Successfully used tunnels to provide connectivity to Jupyter notebooks, front-end connecting to Python cores.
- Dotscience operator automatically deploying Webhook Relay ingress controller.
- All tunnels created automatically through the API, removed once Jupyter is offline.
- ML predictions (inference) are served over the tunnels.