
Using Google Firestore for a Golang backend application
Switching from internal KV store to a Google Firestore can be quick and easy
Usually, when I need a database I just pick Postgres or embedded key-value stores such as the excellent boltdb, badger from dgraph or Redis (if I need a KV store but shared between several nodes). With flexibility comes the burden of maintenance and sometimes additional cost. In this article, we will explore a simple Golang backend service that will use Google Firestore as storage.
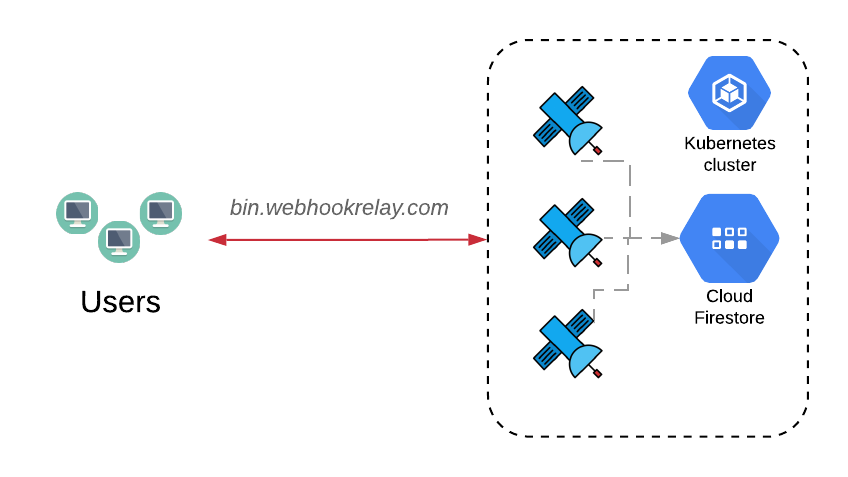
When I started working on a simple project called bin.webhookrelay.com, I picked Badger as a key-value store, attached a persistent disk to a Kubernetes pod and launched it.
bin.webhookrelay.com is a free service that allows you to capture webhook or API requests for testing purposes. It also lets you specify what response body and status code to return, as well as set an optional response delay.
The data model was (and still is) simple:
- Bin that has a certain configuration like what status code to return, response body, content-type header, and response delay.
- Request which is the actual captures webhook request with bin ID, request body, headers, and query.
Most of the time, KV stores such as boltdb or badger are great for such use cases. Problems arise when you want to either scale horizontally or have a rolling update strategy meaning that a number of instances of your application would have to surge during the update. While Kubernetes is great for running pretty much any workload, an update where it has to detach a persistent disk and reattach it to a new pod can lead to downtime and just generally slow updates. I always try to avoid such scenarios, however, webhook bin service was suffering from it.
This time, I decided to try out Cloud Firestore. You probably have already heard about Firestore (previously known as Firebase) and that it is very popular amongst mobile app developers who need to have a database for their Android and iOS apps. Apparently, it can also provide a really nice developer UX for backend applications! :)
Setting it up
For authentication, Golang Firestore client uses a standard mechanism that relies on a service account. Basically, you need to go to:
- GCP console
- Click on IAM & admin
- Go to service accounts (on the left navigation bar)
- Create a new service account with Firestore permissions
- Download the file, you can now use it for authentication
Docs can be found in the Google Cloud authentication section.
Application code is surprisingly simple. You get the client using Google application credentials, project ID and that's it:
func NewFirestoreBinManager(opts *FirestoreBinManagerOpts) (*FirestoreBinManager, error) {
ctx := context.Background()
var options []option.ClientOption
if opts.CredsFile != "" {
options = append(options, option.WithCredentialsFile(opts.CredsFile))
}
// credentials file option is optional, by default it will use GOOGLE_APPLICATION_CREDENTIALS
// environment variable, this is a default method to connect to Google services
client, err := firestore.NewClient(ctx, opts.ProjectID, options...)
if err != nil {
return nil, err
}
return &FirestoreBinManager{
binsCollection: opts.BinsCollection, // our bins collection name
reqsCollection: opts.ReqsCollection, // our requests collection name
client: client,
pubsub: opts.Pubsub,
logger: opts.Logger,
}, nil
}
Adding and updating bins
When creating a document, you can specify document ID and just pass in the whole golang struct without first marshaling it into JSON:
func (m *FirestoreBinManager) BinPut(ctx context.Context, b *bin.Bin) (err error) {
_, err = m.client.Collection(m.binsCollection).Doc(b.GetId()).Set(ctx, b)
return err
}
Note that we supply collection name: Collection(m.binsCollection), ID: Doc(b.GetId()) and set the struct fields Set(ctx, b).
This really saves time! An alternative with a KV store would be something like:
func (m *BinManager) BinPut(ctx context.Context, b *bin.Bin) (err error) {
b.Requests = nil
encoded, err := proto.Marshal(b)
if err != nil {
return err
}
return m.storage.Store(ctx, "bins/"+b.Id, encoded, nil)
}
...
// store package
func (s *Storage) Store(ctx context.Context, id string, data []byte, metadata map[string]string) error {
err := s.db.Update(func(txn *badger.Txn) error {
// Your code here…
return txn.Set([]byte(id), data)
})
return err
}
Deleting
To delete a bin in our case means deleting both the bin document and all associated webhook requests with it:
func (m *FirestoreBinManager) BinDelete(ctx context.Context, binID string) error {
_, err := m.client.Collection(m.binsCollection).Doc(binID).Delete(ctx)
if err != nil {
m.logger.Errorw("failed to delete bin doc by ref",
"error", err,
)
}
// Now, get all the requests and delete them in a batch request
iter := m.client.Collection(m.reqsCollection).Where("Bin", "==", binID).Documents(ctx)
numDeleted := 0
batch := m.client.Batch()
for {
doc, err := iter.Next()
if err == iterator.Done {
break
}
if err != nil {
return fmt.Errorf("Failed to iterate: %v", err)
}
batch.Delete(doc.Ref)
numDeleted++
}
// If there are no documents to delete,
// the process is over.
if numDeleted == 0 {
return nil
}
_, err = batch.Commit(ctx)
return err
}
Limitations
While it is very easy to store, retrieve and modify documents, some people will miss SQL type queries that can aggregate, count records and do other useful operations in the database. For example, to track document counts, you will have to implement a solution similar to one described here. My suggestion would be to spend more time planning data structure and what kind of operations are you planning to use before embarking on this journey :)
Conclusion
While being a bit skeptical at first, I quickly started liking Firestore. While running a managed Postgres would allow me to easier switch cloud providers, it would also make it more expensive to run. Keeping storage interface small means that you can implement Postgres (or any other database) driver in a matter of hours so then the most important things to look for are:
- How much maintenance the solution requires
- Cost
- Performance
Useful resources: