
Durable webhook retries: a live demo of webhooks that never give up
We launched durable retries — webhooks persisted and retried with backoff for up to 30 days. We built an endpoint that fails 80% of the time to prove it.
A webhook you don't receive might as well have never happened. A deploy, a restart, a database hiccup, a five-minute outage — miss the delivery and the event is usually gone for good. Most providers retry a handful of times over a few minutes, then give up.
Today we're launching durable retries: turn it on for any destination and Webhook Relay takes responsibility for getting the event there. Every webhook is saved to durable storage the moment it arrives, and if the first attempts fail, delivery doesn't stop — it backs off and keeps trying, all the way out to 30 days.
Talking about reliability is easy, though. So we built something that fails on purpose and watched durable retries win anyway.
Meet flakey-script: an endpoint that fails 80% of the time
flakey-script is a tiny, open-source Node.js webhook receiver with one job: be unreliable in a realistic way.
Send it an event like this:
{ "type": "event", "id": "xx-123", "data": "test" }
and for each unique id it behaves like a real endpoint having a bad day:
- While an
idis younger than an hour, it returns500about 80% of the time (and200the rest — the occasional lucky success). - Once that
idis at least an hour old, it always returns200— the "endpoint has recovered" moment. - Once an
idhas succeeded, every later retry for it is an idempotent200: it's never processed twice.
State lives on the filesystem, so it survives restarts and you can watch every id converge on delivered over time. The whole thing is a couple hundred lines of dependency-free Node — read it on GitHub.
The setup
The demo wires flakey-script up to Webhook Relay using a tunnel so the local app is reachable as a public destination — no inbound ports, no public IP:
sender ──▶ Webhook Relay ──(durable retries)──▶ tunnel ──▶ flakey-script
├─ ~80% of early attempts → 500
└─ same id, 1h later → 200 (always)
It runs as a two-container docker compose stack — the app plus the Webhook Relay agent that connects the tunnel:
- Create a bucket (
durable-demo) with a public endpoint to receive webhooks. - Create a tunnel pointing at
http://flakey-script:3000and run the agent in compose. - Add a public output to the bucket, set its destination to the tunnel URL, and switch on durable delivery with the Medium (~16 h) schedule.
- Fire a batch of 25 webhooks at the bucket and walk away.
That's it. Everything after step 4 is Webhook Relay's problem now.
Watching it converge
Within seconds, the request log fills with attempts. Each delivery shows its status: sent when the endpoint returns 2xx, stalled when it's failed so far and is waiting for the next retry.
The fast-retry phase does most of the work immediately — a single POST becomes a flurry of attempts, and the lucky ones land right away. Here's the receiver's own dashboard a few minutes in: 25 events received, 20 delivered, 5 still retrying, and 98 total delivery attempts behind the scenes.
The five stragglers are the unlucky ones — the events that kept rolling 80% failures. They don't get dropped. After the 15-minute handoff window they move to the durable retry engine, which keeps trying on an exponential-backoff schedule. Each one is guaranteed to land on its next retry after it crosses the one-hour mark. No manual reconciliation, no lost events — the whole batch converges on delivered.
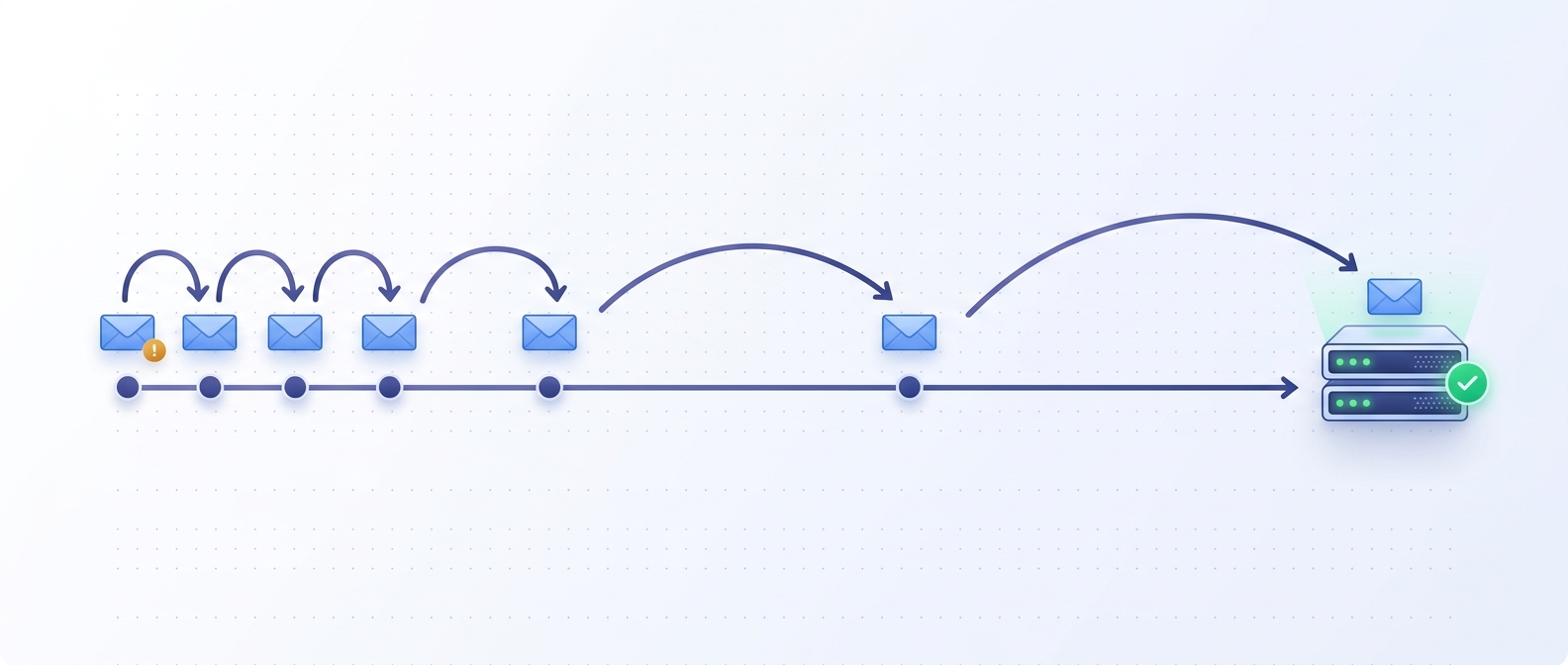
Each retry waits a little longer than the last, so a struggling server gets room to recover instead of being hammered while it's already down.
What convergence actually looks like
Here's the same story as a timeline you can explore. Press play (or drag the slider) to watch 50 webhooks move from retrying to delivered over an hour and a bit, and flip to Retry attempts to see the delivery effort behind the curve. Hover anywhere for the exact numbers.
Three phases stand out, and they're the same three you'll see in your own dashboard:
- The fast-retry burst (0–15 min). The first attempt becomes a flurry of attempts, and most events land almost immediately — about half are delivered within the first couple of minutes. This is where the bulk of the work happens, with no delay you'd notice.
- The stubborn tail (15–60 min). A handful of events keep rolling failures. Instead of dropping them, Webhook Relay hands them to durable retry and keeps them queued with growing backoff — the retrying band thins out slowly.
- The one-hour guarantee (60 min+). As each remaining event crosses the recovery threshold, its next retry finally lands. The curve closes to 100%: every webhook delivered, nothing reconciled by hand.
That last phase is the whole point of durability — the long tail of "impossible" deliveries that a few minutes of provider retries would have lost forever.
The best part: turn it off
Here's the test that really makes the point. Stop the receiver entirely — close the laptop, kill the containers, go to lunch. To Webhook Relay that's just another outage. The events sit safely in durable storage, and the retries you'd otherwise have lost are still queued. Start everything back up and, once the events are old enough, they all land. The "downtime" became a non-event.
Why this matters
The durability you'd normally bolt together from a queue, a database and a cron job — done for you, per destination, with a single switch:
- Payments and billing. A processor or your billing service goes down for an hour. The confirmations wait, then deliver.
- Deploys without dropped events. Ship in the middle of the day; webhooks that arrive during the restart queue up and land when your service is healthy again.
- Flaky partner endpoints. Integrating with a service that returns 500s under load? Let it fail and recover on its own schedule instead of writing your own retry plumbing.
- Internal endpoints. Durable retries cover services behind your firewall too — even ones that were offline when the event arrived.
One thing to remember: be idempotent
Because durable delivery is at-least-once, the same event can legitimately arrive more than once (your endpoint processed it but the 200 got lost on the way back, so we retry). That's exactly why flakey-script keys on the event id and treats a repeat as a no-op. Do the same in your handler: deduplicate on a stable id, return 2xx once you've safely accepted an event, and a 5xx to ask for a retry. The durable webhooks guide covers the pattern in detail.
Try it yourself
- ⭐ Run the demo: github.com/webhookrelay/flakey-script
- 📖 Read the guide: Durable webhooks: reliable delivery with automatic retries
- 🧩 Feature overview: Durable retries
Ready to make sure no webhook slips through? Create a free account and turn on durable retries for your first destination.